Google has introduced a new AI model that takes computer interaction to the next level. Called the Gemini 2.5 Computer Use model, it’s a specialized version of Gemini 2.5 Pro designed to let AI agents directly use websites and apps — not through APIs or code, but through the same graphical interfaces that humans use.

Gemini 2.5 Computer Use model, new specialized model built on Gemini 2.5 Pro’s visual understanding and reasoning capabilities that powers agents capable of interacting with user interfaces (UIs). It outperforms leading alternatives on multiple web and mobile control benchmarks, all with lower latency. Developers can access these capabilities via the Gemini API in Google AI Studio and Vertex AI.
💡 Read next: OpenAI Sora 2 Capabilities & Real-World Uses Explained
How it works
The model’s core capabilities are exposed through the new `computer_use` tool in the Gemini API and should be operated within a loop. Inputs to the tool are the user request, screenshot of the environment, and a history of recent actions.
👉 Observe: The model receives a screenshot and contextual information about the current screen.
👉 Decide: It analyzes the interface, determines the next logical step (like clicking a login button), and produces a function call describing that action.
👉 Act: A client-side automation layer executes that action on the real interface.
👉 Repeat: A new screenshot is captured, and the loop continues until the goal is met.
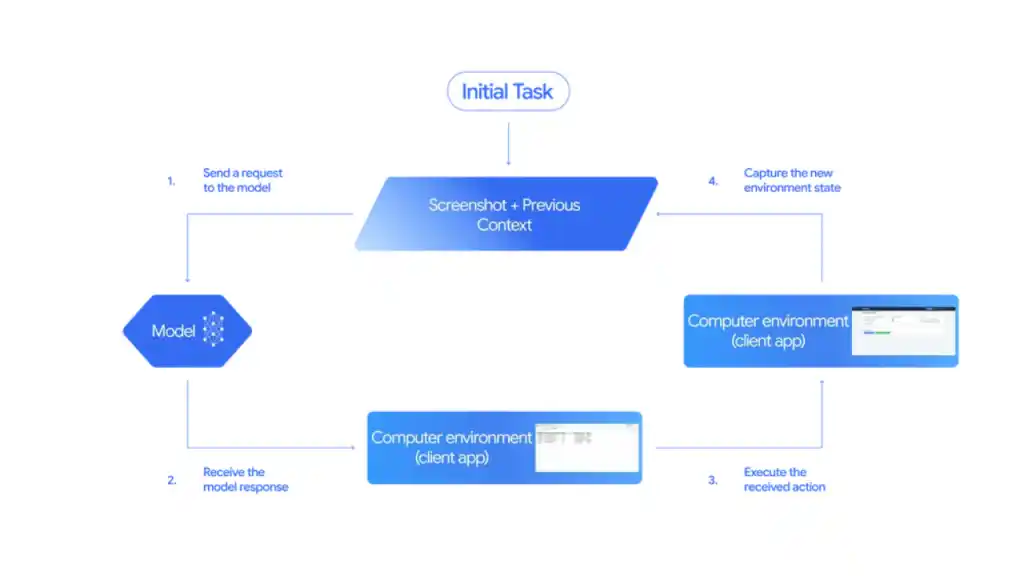
The Gemini 2.5 Computer Use model is primarily optimized for web browsers, but also demonstrates strong promise for mobile UI control tasks. It is not yet optimized for desktop OS-level control.
What Makes Gemini 2.5 Different
Gemini 2.5 builds on the core intelligence of the Gemini 2 series but adds a new layer of real-world computer control.
Here’s what sets it apart:
- Enhanced Context Understanding: The model can handle longer, more complex tasks without losing context.
- Computer Use Capability: Gemini can now open files, manage spreadsheets, browse websites, send emails, and execute workflows directly.
- Multi-Modal Integration: It seamlessly blends text, image, and screen understanding for a more natural experience.
- Privacy-Centric Design: All actions are logged and can be monitored or restricted — giving users full control.
Gemini 2.5 vs ChatGPT and Other AI Models*
While OpenAI’s ChatGPT has already introduced strong reasoning and tool-use capabilities, Google’s Gemini 2.5 takes a slightly different path — focusing on native computer-level integration.
| Features | Gemini 2.5 | ChatGPT(GPT_5) |
|---|---|---|
| Computer Uses | Native integration on ChromeOS & Android | Via API & plugins |
| File Handling | Built-in | Available through tools |
| Image+text tasks | Strong | Strong |
| Ideal for | Productivity & workflow automation | Reasoning & creative tasks |
| Context Memory | Extended | Advanced |
Gemini’s tight link with Google’s ecosystem — Gmail, Drive, Docs, and Sheets — makes it a serious contender for anyone relying on Google tools for work
How it performs
The Gemini 2.5 Computer Use model demonstrates strong performance on multiple web and mobile control benchmarks. The table below includes results from self-reported numbers, evaluations run by Browserbase and evaluations we ran ourselves.
Performance Benchmarks
Google says Gemini 2.5 Computer Use has demonstrated leading results in multiple interface control benchmarks, particularly when compared to other major AI systems including Claude Sonnet and OpenAI’s agent-based models.
Evaluations were conducted via Browserbase and Google’s own testing.
🌍 Related: WhatsApp’s Massive Privacy Upgrade 2025 — Use Username Instead of Number Sharing
Some highlights include:
- Online-Mind2Web (Browserbase): 65.7% for Gemini 2.5 vs. 61.0% (Claude Sonnet 4) and 44.3% (OpenAI Agent)
- WebVoyager (Browserbase): 79.9% for Gemini 2.5 vs. 69.4% (Claude Sonnet 4) and 61.0% (OpenAI Agent)
- AndroidWorld (DeepMind): 69.7% for Gemini 2.5 vs. 62.1% (Claude Sonnet 4); OpenAI’s model could not be measured due to lack of access
- OSWorld: Currently not supported by Gemini 2.5; top competitor result was 61.4%

Gemini 2.5 Computer Use outperforms leading alternatives on multiple benchmarks
The model offers leading quality for browser control at the lowest latency, as measured by performance on the Browserbase harness for Online-Mind2Web.
Safety first
A model that can control a computer naturally raises safety concerns. Google acknowledges this and has implemented multiple guardrails. Every proposed action is checked by a safety service before execution, filtering out anything that could be harmful, malicious, or risky.
Certain actions, such as making financial transactions or sending data, require explicit user confirmation. Developers can also define “forbidden actions” to ensure the model stays within safe boundaries.
- Per-step safety service: An out-of-model, inference-time safety service that assesses each action the model proposes before it’s executed.
- System instructions: Developers can further specify that the agent either refuses or asks for user confirmation before it takes specific kinds of high-stakes actions. (Example in documentation).
Final Thoughts
Google’s Gemini 2.5 isn’t just an upgrade — it’s a statement. It signals where the future of AI is heading: AI that doesn’t just think, but acts.
If Gemini continues on this path, it could redefine what we expect from digital assistants, making them integral partners in work and life.
With the Computer Use model, Gemini 2.5 marks a shift from passive intelligence to active capability. Instead of simply responding to prompts, it can take initiative, following complex instructions through multi-step UI interactions.
For now, Google’s Gemini 2.5 Computer Use is still experimental, but it represents a pivotal leap: an AI that doesn’t just talk about the web – it uses it.
📸 Stay Updated!
Follow us on Instagram for the latest business, world news & tech trends.
➜ Follow @FasturiousOfficial